
In college, my roommates and I once saw an advertisement on television that we thought was hilarious. A young guy was talking to a young woman. I don’t quite recall the lead-up, but somehow the guy made an error, and admitted it. Near the end of the ad she said “I like a guy who can admit that he’s wrong”. The clearly-infatuated guy responded a bit over-enthusiastically, saying “Well actually, I’m wrong a LOT!” This became a good-natured joke/mantra in our co-op: when someone failed to do their dishes, or cooked a less-than-edible meal for the group, everyone would chime in “I’m wrong a lot!”
Twenty years later, I find myself admitting I was wrong – but hopefully not a lot.
A bunch of evolutionary ecology theory makes a very reasonable assumption: phenotypically similar individuals, within a population, are likely to have more similar diets and compete more strongly than phenotypically divergent individuals within that same population. This assumption underlies models of sympatric speciation (1) as well as the maintenance of phenotypic variance within populations (2, 3). But it isn’t really tested directly very much. In 2009, a former undergraduate and I published a paper that lent support to this common assumption (4). The idea was simple: we measured morphology and diet on a large number of individual stickleback from a single lake on Vancouver Island, then tested whether pairwise difference in phenotype (between all pairwise combinations of individuals) was correlated with pairwise dissimilarity in diet (measured by stomach contents, or stable isotopes). The prediction was that these should be positively correlated. And that’s what we reported in our paper, with the caveat (in the title!) that the association was weak.

An excerpt from Bolnick and Paull 2009 that still holds, showing the theoretical expectation motivating the work.
Turns out, it was really, really weak. Because we were using pairwise comparisons among individuals, we used a Mantel Test to obtain P-values for the correlation between phenotypic distance, versus dietary overlap (stomach contents) or difference (isotopes). I cannot now reconstruct how this happened, but I clearly thought that the Mantel test function in R, which I was just beginning to learn how to use, reported the cumulative probability rather than the extreme tail probability. So, I took the P reported by the test, subtracted it from 1 to get what I thought was the correct number, and found I had a significant trend. Didn’t look significant to my eye, but it was a dense cloud with many points so I trusted the statistics and inserted the caveat “weak” into the title. I should have trusted my ‘eye-test’. It was wrong.
Recently, Dr. Tony Wilson from CUNY Brooklyn tried to recreate my analysis, so that he could figure out how it worked and apply it to his own data. I had published my raw data from the 2009 study in an R package (5), so he had the data. But he couldn’t quite recreate some of my core results. I dug up my original R code, sent it to him, and after a couple of back-and-forth emails we found my error (the 1-P in the Mantel Test analysis). I immediately sent a retraction email to the journal (Evolutionary Ecology Research), which will be appearing soon in the print version. So let me say this clearly, I was wrong. Hopefully, just this once.
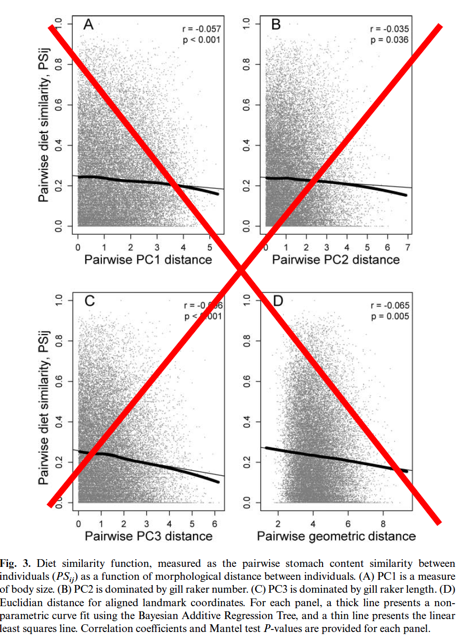
The third and fourth figures in Bolnick and Paull 2009 are wrong. The trend is not significant, and should be considered a negative result.
I want to comment, briefly, on a couple of personal lessons learned from this.
First of all, this was an honest mistake made by an R-neophyte (me, 8 years ago). Bolnick and Paull was the first paper that I wrote using R for the analyses. Mistakes happen. It is crucial to our collective scientific endeavor that we own up to our individual mistakes, and retract as necessary. It certainly hurt my pride to send that retraction in (Fig. 3), as it stings to write this essay, which I consider a form of penance. Public self-flagellation by blogging isn’t fun, but it is important when justified. We must own up to our failures. Something, by the way, that certain (all?) politicians could learn.

Drowning my R-sorrows in a glass of Hendry Zinfandel.
Second, I suspect that I am not the only biologist out there to make a small mistake in R code that has a big impact. One single solitary line of code, a “1 –“ that does not belong, and you have a positive result where it should be a negative result. Errors may arise from a naïve misunderstanding of the code (as was my problem in 2008), or from a simple typographic error. I recently caught a collaborator (who will go unnamed) in a tiny R mistake that accidentally dropped half our data, rendering some cool results non-significant (until we figured out the error while writing the manuscript). So: how many results, negative or positive, that enter the published literature are tainted by a coding mistake as mine was. We just don’t know. Which raises an important question: why don’t we review R code (or other custom software) as part of the peer-review process? The answer of course is that this is tedious, code may be slow to run, it requires a match between the authors’ and reviewers’ programming knowledge, and so on. Yet, proof-reading, checking, and reviewing statistical code is at least as essential to ensuring scientific quality as proof-reading our prose in the introduction or discussion of a paper. I now habitually double- and triple-check my own, and my collaborators’, R code.
Third, R is a double-edged sword. Statistical programming in R or other languages has taken evolution and ecology by storm in the past decade. This is mostly for the best. It is free, and extremely powerful and flexible. I love writing R code. One can do subtle analyses and beautiful graphics, with a bit of work learning the syntax and style. But with great power comes great responsibility. There is a lot of scope for error in lengthy R scripts, and that worries me. On the plus side, the ability to save R scripts is a great thing. I did my PhD using SYSTAT, doing convoluted analyses with a series of drag-and-drop menus in a snazzy GUI program. It was easy, intuitive, and left no permanent trail of what I did. So, I made sure I could recreate a result a few times before I trusted it wholly. But I simply don’t have the ability to just dust off and instantly redo all the analyses from my PhD. Saving (and annotating!!!!!) one’s R code provides a long-term record of all the steps, decisions, and analyses tried. This archive is essential to double-checking results, as I had to do 8 years after analyzing data for the Bolnick and Paull paper.
Fourth, I found myself wondering about the balance between retraction and correction. The paper was testing an interesting and relevant idea. The fact that the result is now a negative result, rather than a positive one, does not negate the value of the question, nor does it negate some of the other results presented in the paper about among-individual diet variation. I wavered on whether to retract, or to publish a correction. In the end, I opted for a retraction because the core message of the paper should be converted to a negative result. This would entail a fundamental rewriting of more than half the results and most of the discussion. That’s more work than a correction could allow. Was that the right approach?
To conclude, I’ve recently learned through painful personal experience how risky it can be to use custom code to analyze data. My confidence in our collective research results will be improved if we can find a way to better monitor such custom code, preferably before publication. As Ronald Reagan once said, “Trust, but verify”. And when something isn’t verified, step forward and say so. I hereby retract my paper:
Daniel I. Bolnick and Jeffrey S. Paull. 2009. Morphological and dietary differences between individuals are weakly but positively correlated within a population of threespine stickleback. Evol. Ecol. Res. 11, 1217–1233.I still think the paper poses an interesting question, and might be worth reading for that reason. But if you do read (or, God forbid, cite) that paper, keep in mind that the better title would have been: “Morphological and dietary differences between individuals are NOT positively correlated within a population of threespine stickleback” , and know that the trends shown in Figures 3 and 4 of the paper are not at all significant. Consider it a negative-result paper now.
The good news is that now we are in greater need of new tests of the prediction illustrated in the first picture, above.

A more appropriate version of the first page of the newly retracted paper.
1. U. Dieckmann, M. Doebeli, On the origin of species by sympatric speciation. Nature 400, 354-357 (1999).
2. M. Doebeli, Quantitative genetics and population dynamics. Evolution 50, 532-546 (1996).
3. M. Doebeli, An explicit genetic model for ecological character displacement. Ecology 77, 510-520 (1996).
4. D. I. Bolnick, J. Paull, Diet similarity declines with morphological distance between conspecific individuals. Evolutionary Ecology Research 11, 1217-1233 (2009).
5. N. Zaccarelli, D. I. Bolnick, G. Mancinelli, RInsp: an R package for the analysis of intra-specific variation in resource use. Methods in Ecology and Evolution, DOI:10.1111/2041-210X.12079, (2013).




A difficult but important experience I am sure, but my respect for your scientific integrity has only grown Dan! Thanks for sharing this experience, which I think is important for new and old scientists alike to read.
ReplyDeleteHi Dan
ReplyDeleteThanks for the interesting blog, and honest disclosure. The 'coding mistake' is an issue that bothers me a lot, and I'm sure it's responsible for various results out there. In their recent study Smaldino and McElreath (http://rsos.royalsocietypublishing.org/content/3/9/160384) argued that with the current structure of scientific evaluation there is a strong selection for scientist allowing false-positive findings (in this context, a false positive finding will be any erroneous result arising from not checking your code well enough). Unfortunately I agree with their conclusion.
So what can we do? I agree that reviewing one's code as a part of the peer review would have been ideal, but its probably not feasible from the reasons you mentioned (time, effort, matching skills etc). The now-popular requirement of publishing the raw data is good first step in the right directions since it allows an interested/skeptic reader to reproduce them. If he/she fails it may lead to discovering these errors, like in the case you described.
Perhaps a better alternative that is still feasible is to publish ALSO your codes. An error can still go unnoticed during publication, but at least there are much higher chances that a reader will try to run them to reproduce the results, and will look on them so see if he/she understands them (and then, maybe spot the errors).
So, I think that adding the codes as an appendix is an appropriate next step in the right direction. It’s becoming common in modeling and methods papers (e.g. my own in MEE). As a reviewer I often encouraged (but haven’t demanded) authors to do so. Perhaps should be more inclusive in that, and walk the extra mile for including the codes (on top of the raw data), in empirical studies.
Thanks
Orr Spiegel, Davis
This has been a common suggestion, and a good one. I remember Mike Whitlock saying, when Dryad first began, that they couldn't require publication of code due to legal reasons involving the difference between data and written code, the latter involving different copyright restrictions. Don't know the details, but should find out. This is certainly a great suggestion. More work for the authors, but they will likely annotate, proof-read, and feel more compulsion to be careful.
Delete